不确定性学习
参考资料
https://zhuanlan.zhihu.com/p/95774787
不确定性介绍
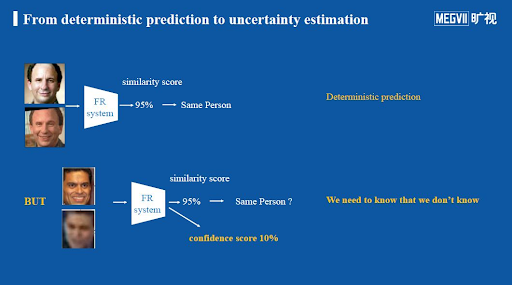
对于某个输入,模型只能给出一个特定的结果,比如:
对于人脸识别,输入人脸的图像,模型输出一个embedding(高维空间中的某一确定点);
对于分类网络,输入某个图像,模型输出类别的概率的预测值;
问题就是,当训练数据和测试数据分布不一致、输入的图像并不属于分类网络的分类类别、训练或测试图像带有噪声等情况出现时,模型并不能输出对预测结果的置信度,导致错误的结果。
在金融、医疗、自动驾驶等高风险领域,模型精确性非常重要,需要模型在输出预测结果的同时,还要对预测结果进行置信度的判断,当置信度较低时,可以由人工介入,防止不良后果。
不确定性的分类
从模型和数据角度,一般分成两类:
数据不确定性/偶然(Aleatoric)不确定性:
数据内在的噪声导致,比如采集工具/标注包含的噪声,无法通过采集更多的数据来解决,需要通过提升数据源准确率来改善。
模型不确定性/认知(Epistemic)不确定性:
由于训练方式、训练数据少等原因导致,是模型参数本身的不确定性,可以通过优化训练方式、数据驱动的方式来解决。
比如:训练数据为未增强数据,测试数据包含了增强后的数据,导致模型的预测结果错误。
深度学习不确定性的建模
模型不确定性 [****参考视频****]
对于训练好的模型,权重已经固定,对于相同的输入,输出也是相同的。主要有两种方法引入不确定性:贝叶斯神经网络BNN,模型融合。
- 贝叶斯神经网络 BNN [****参考****] 引入贝叶斯法则,模型的参数不是固定的数值,而是服从某个分布。在训练和推理的过程中,模型的参数从分布中采样而不断变化,根据不同参数预测值的方差,来建模模型参数的不确定性。
通用神经网络的学习可视为最大似然估计(MLE):
为参数
(高斯分布的先验为L2正则化,拉普拉斯分布的先验为L1正则化)
贝叶斯估计目标:求后验分布
难点在于:1、
一般采用以下几种方法来估计:
1、Approximating the integral with MCMC,即用马尔可夫-蒙特卡洛采样来近似分母的积分
2、variational inference,用一个分布q去近似后验分布p,KL最小化分布间差异
3、MC-dropout(蒙特卡洛 dropout)
- 马尔可夫链蒙特卡洛(MCMC) [****参考****] MCMC:一种通过在概率空间中随机采样来近似感兴趣参数的后验分布的方法
蒙特卡洛估计:通过重复生成随机数,进行固定参数的估计(比如:圆周率的估计)
马尔可夫链:事件相互关联概率的序列,下一个事件的结果由上个事件结果根据一组固定概率来确定
整体方法:
1、确定参数的先验分布;
2、采样参数的初始值,作为当前参数值;
3、根据当前参数值,M-H/Gibbs采样下一个参数值;
4、计算当前参数值及下一个参数值的后验概率比值,作为接受下一个参数值的概率;
5、重复3、4步骤,最终将被采样的参数数值的频率分布作为后验分布的近似;
- 变分推断(variational inference) [****参考****] 核心点是,用一个分布
逼近后验分布 ,通过最小化分布之间的KL散度来进行实现:
第一项表示变分后验分布与先验分布的KL散度,第二项表示对样本的拟合程度(基于变分后验分布的重建似然函数)
- MC-DropOut [****参考论文****] 从贝叶斯理论的角度,将 Dropout 解释为高斯过程的贝叶斯近似。
测试模式下,打开dropout,多次前向传播后得到不同的输出,统计均值和方差/熵,即为模型的预测结果及不确定性。
- 模型融合 从数据集中进行不同方式的采样,训练多个模型,对于测试的数据,每个模型进行前向,统计得到均值和方差,即为模型预测结果后和不确定性。
MC-Dropout可以视为特殊的模型融合方式。
数据不确定性
深度学习不确定性的组合
回归问题
假设预测值遵循高斯分布
当样本难以优化,为了使
换一种角度,也可以理解为,假设GT遵循Dirac Delta分布,目标函数在优化预测分布和GT分布之间的KL散度。
分类问题
对于输入样本
假设
其中
CV相关应用
分割,边缘部分?
检测,回归部分?
识别相关
PFE: Probabilistic Face Embeddings [****pdf****][****code****] [ICCV2019]
主要思想:人脸的特征在特征空间不是确定的一点,而是变成高斯分布,均值表示特征最可能的数值,方差表示数值的不确定性。PFE可以提升人脸识别性能,估计出的不确定性进行人脸的匹配,对需要风险控制的识别系统非常重要。
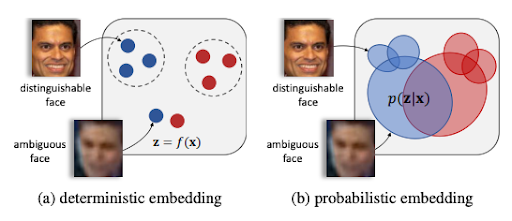
确定性Embedding存在的问题:确定性的特征代表模型将人脸图像表达为特征空间中一个确定的点,在误差很小的情况下,两个点之间的距离可以明确的表示相似度,但是在图像质量不好的情况下,预测的特征可能会存在歧义或者语义确实,导致特征点产生较大的偏移。非受控的场景(监控等),人脸存在较大方差的变化,任意特征都可能缺失。
PFE提出的改进:模型的输出不再是特征空间的一个点,而是特征空间中的分布估计。分布的中心就是特征估计值,方差就是估计值的不确定性。
它通过两个方面缓解非受控下人脸识别的问题:
1、比对时,PFE对不确定的特征维度进行惩罚,且更加注意确定的特征;
2、对低质量的输入,不确定性的估计可以反馈给用户,避免错误的识别结果。
在人脸库中,当相同id有多张照片需要聚合时,可以结合PFE得到更确定的分布,提升识别能力。
PFE里的不确定性表示为数据不确定性。
相关工作
人脸的概率表达:如何建模人脸的概率分布?
通常用概率分布、子空间或者流形来表示人脸特征。一般这种方法输入的是一组图片,使用分布间的相似度来进行距离计算(KL散度等),但是不会对不确定性进行惩罚。PFE将单张人脸图像编码成特征空间中的分布,使用 uncertainty-aware log似然得分来进行分布的比较。
质量相关的人脸Pooling
人脸Pooling:在进行视频人脸/人脸模版比对的时候,聚合多个人脸特征,生成一个特征。一般会有个额外的模块来预测人脸的质量,进行加权的pooling。在这里可以直接用PFE生成的概率来解释这类方法,也可以学习更通用的解决。
确定性embedding的局限性:从理论和实验的角度进行阐述
符号定义:
人脸特征的训练就是找到特征空间
对于确定性的特征,逆映射是个狄拉克
只要输入
如果偏移有界,那么还是可以得到较小的类内距离。但是人脸识别是无约束的,导致无法令偏移有界:通过假设和实验来证明:
假设:给一组人脸照片,确定性的embedding将将它们映射到同一点,距离永远为0,即使这些照片质量差到无法检测到人脸。相似或相同的照片并不一定意味着他们属于同一个人的概率会很高。实验:拿LFW的高质量图片,构造高斯模糊、遮挡和噪声,计算相似度:
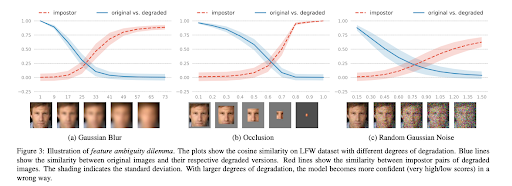
随着质量不断下降,相同ID的相似度降低为0,不同ID的相似度变为1。这代表无约束场景的识别中存在的两种错误类型:不同人的低质照片的误识别 vs 相同人不同质量照片的误拒绝。
Feature Ambiguity Dilemma:确定性的模型对有歧义的图片进行特征估计会存在所谓的特征歧义。实验找了IJB-A中高分的neg-pair和低分的pos-pair,发现确实存在这样的问题,因此认为特征空间中存在dark space,ambiguous输入会被映射到这块空间中,无法用通用的距离公式进行相似度的度量。

PFE
将不确定性编码到人脸特征中,并在匹配的的时候修正匹配结果。
与确定性模型的区别是,PFE预测的是特征空间的分布
为了减少复杂度,假设每个维度特征是独立分布的,这里使用对角协方差矩阵。模型的输出包括:
1、中心
2、不确定性
如何匹配
输入一对人脸
实际使用了log likelihood:
$$
(证明:
狄拉克
MLS是对称的,当不确定性一致时,L2距离是MLS的一个特例:
对所有样本,在第
$
当每个样本的不确定性不一致,MLS存在以下性质:
- 注意力机制,公式第一项:确定性更强的维度,权重更大
- 惩罚机制,公式第二项:对高不确定性的惩罚
- 输入的不确定性大,不管他们的均值是否相近,MLS都会很低
- 只有输入的不确定性很小且均值互相靠近,MLS才会很高 当网络能够正确估计
时,PFE可以解决feature ambiguity dilemma
基于PFE的特征融合
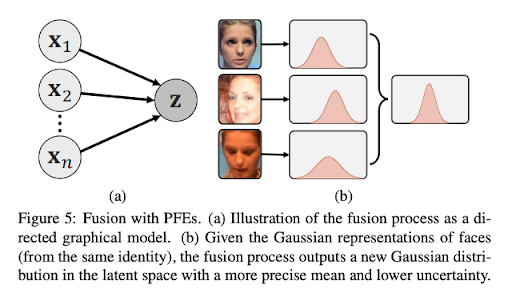
给出一个人的n张照片
证明:
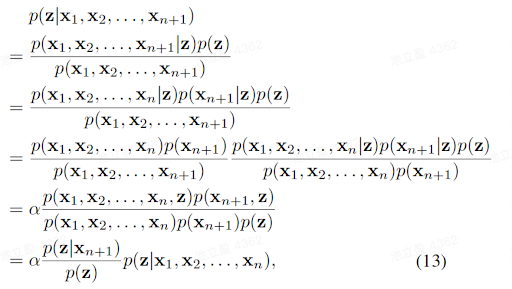
给
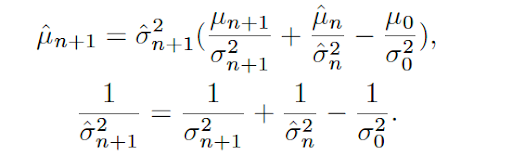
可以递推得到最终的均值和方差:
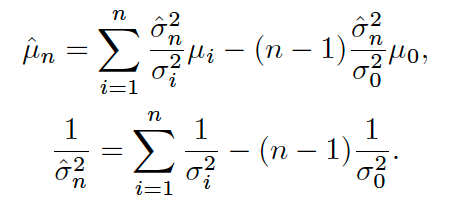
由于
实际使用时,为了防止均值方差的更新受图像数量的影响(视频中存在大量冗余帧),在每个维度上取最小值作为新的不确定性。
当图片上每个维度的不确定性
训练方式
Stage-wise training策略
finetune方式,需要已训练好的确定性的识别模型,满足PFE的要求(输出特征与ID相关)。
冻结模型参数,令
添加了一个不确定性预测模块来预测
实际上是在最大化
https://zhuanlan.zhihu.com/p/98756147
DUL: Data Uncertainty Learning in Face Recognition [****pdf****][code] [CVPR2020]
https://zhuanlan.zhihu.com/p/133658997
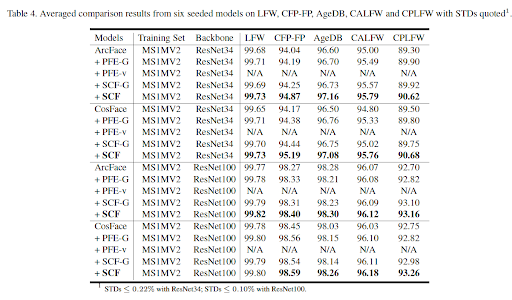
SCF: Spherical Confidence Learning for Face Recognition [****pdf****][****code****] [CVPR2021]
主要贡献:从理论和实验分析了PFE应用在spherical 确定性embedding时两个主要的失败原因。提出了在spherical space上进行人脸确定性学习的框架:将von Mises Fisher密度扩展到r-半径,并推导了优化目标的闭式解,可解释性更强。
PFE在欧式空间中定义了多元独立高斯分布。当应用在spherical embedding时存在问题:
1、理论:在spherical embedding中,独立的多元高斯分布假设失效
2、实验:在spherical densities 的情况下PFE框架训练不稳定,导致PFE很难扩展
Sphere Confidence Face(SCF)与PFE的区别:
- PFE得到是在欧式空间中的不确定性,SCF能得到球面空间中的局部密度,可以看作置信度,引导后续的特征比对和pooling
- SCF不需要PFE中高斯独立分布的假设,以及pair的训练方式。
- PFE最大化MLS(mutual likelihood score),SCF最小化球面上的狄拉克
分布和r-radius vMF分布的KL散度,实验证明有效。
回顾PFE的优化目标:最小化负MLS,其中
预测时,PFE假设人脸
可以去学习一个协方差矩阵。但是这很低效也很难,因为参数量大
在球面进行MLS的最小化是有问题的(导致训练不稳定的原因)。将gaussian分布直接改成球面密度(r-radius vMF)无法解决这个问题。【细节见3.3】SCF通过对人脸的确定性进行建模(而不是不确定性),来避免这两个问题。
r-Radius von Mises Fisher 分布
d维单位球上的条件分布:
其中,
拓展到r-半径的球面
题外话:mVF 与 margin-base Softmax
17年论文"von Mises-Fisher Mixture Model-based Deep learning: Application to Face Verification"已经尝试将vMF与人脸识别技术进行结合,提出von Mises-Fisher Mixture Loss(vMFML)。
基于vMF的分类概率为:
无法复制加载中的内容
vMF可以用在无监督聚类,通过EM方式估计vMF的各个参数。假设每个类别的密度一致(无法复制加载中的内容一致),后验概率简化为:
无法复制加载中的内容
结合交叉熵得到vMFML的损失函数:
无法复制加载中的内容
比对SoftmaxLoss:
无法复制加载中的内容
区别在于:1、vMFML使用了归一化后的特征无法复制加载中的内容;2、均值与分类权重相关无法复制加载中的内容;3、没有bias参数;4、有密度参数无法复制加载中的内容
密度参数无法复制加载中的内容代表特征在均值无法复制加载中的内容附近的紧密程度,增大无法复制加载中的内容可以让特征更靠近类中心,最小化类内距离,最大化类间距离。当无法复制加载中的内容,就可以从不确定的角度来解释L-Softmax/A-Softmax/NormFace等。
优化目标
同PFE一样,定义
分类权重的第
最小化
连续型KL散度计算方式:
优化目标:
关于

理论分析
PFE最大化相同ID pair的MLS, SCL利用了分类权重,最小化球面Dirac delta和r-radius vMF的KL散度。同时也会使靠近分类权重的特征有更高的置信度
- 理论1: 当
趋向于无穷时, 分布趋向于球面Dirac delta分布 - 推论1:
当 (证明略) - 理论2: 当
在(0,正无穷)区间中,质量分 是严格递增函数
SCF-G 的失效原因:
将SCF推广到欧式空间中,得到SCF-G,最小化Euclidean Dirac delta 和 独立多元高斯分布
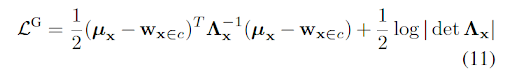
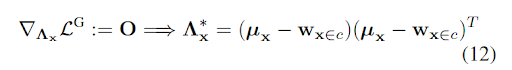
在球面情况下,公式12不成立,因为右侧矩阵非对角线元素可以是非零的。
实验证明SCF优于PFE,且训练更稳定(PFE出现nan)。
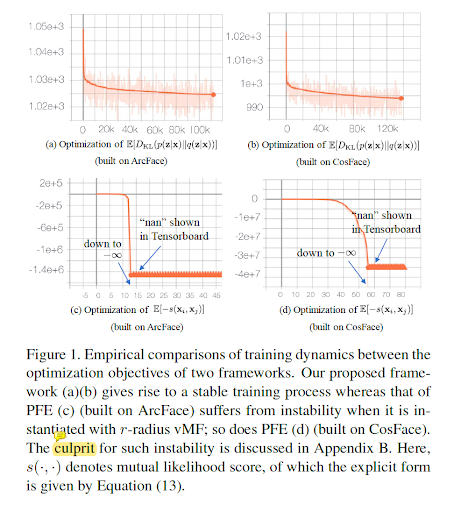
主要是两个原因:1、PFE的通过pairwise的方式进行优化,挑选pair很tricky,容易导致不稳定。2、SCF的优化目标利用了分类权重作为类别的模版,构造球面的Dirac delta。
直观的来说,PFE的目标:如果pos pair分布的重叠率大,对于所有的x,z应该有很大的likelihood
相似度计算
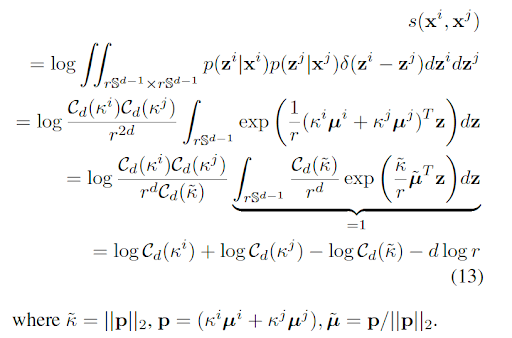
Feature Pooling
由于
Face sets之间通过
实验结果